AI(人工知能)が急速に進化し、私たちの生活やビジネスに浸透する中で、「機械学習」や「ディープラーニング」といった言葉を耳にする機会が増えました。これらの言葉はよく似ていますが、実は明確な違いと関係性があります。「どちらもAIのことでしょ?」となんとなく理解している方も多いかもしれませんが、その違いを知ることは、現代のテクノロジーを理解する上で非常に重要です。
この記事では、AI、機械学習、ディープラーニングの関係性から、それぞれの基本的な意味、そして核心となる違いについて、初心者の方にも理解できるよう、図や例え話を使いながら丁寧に解説していきます。
Contents
まずは全体像!AI・機械学習・ディープラーニングの関係性
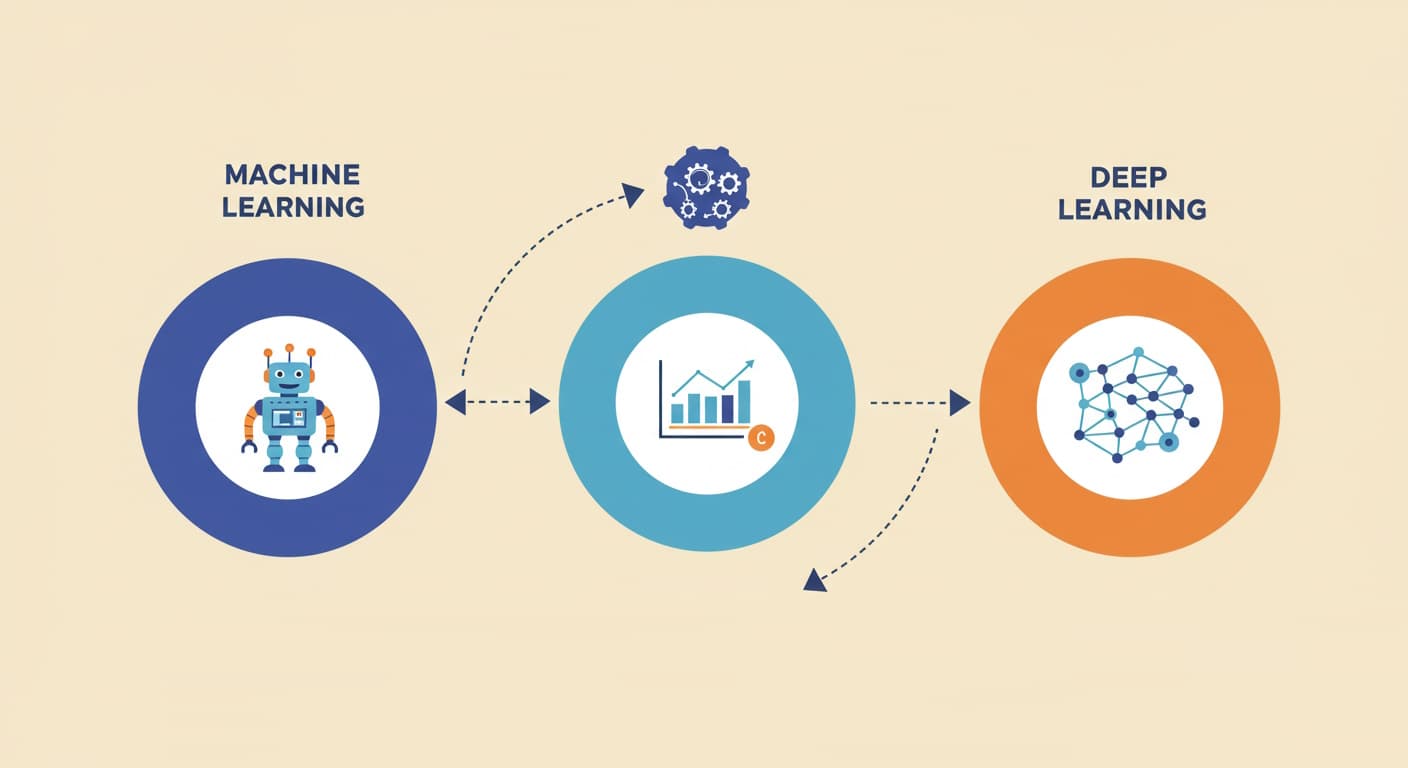
「機械学習」と「ディープラーニング」の違いを理解する前に、まずはこれらの技術が「AI(人工知能)」という大きな枠組みの中で、どのような位置づけにあるのかを知ることが大切です。よく混同されがちなこれらの言葉の関係性は、以下の図のような包含関係で表すことができます。
- AI(Artificial Intelligence:人工知能): 最も広い概念です。人間の知的な活動(考える、学ぶ、判断するなど)をコンピューターで模倣しようとする技術や研究分野全体を指します。「人間のように振る舞う賢いコンピューター」を作るための大きな目標や領域と考えてください。
- 機械学習(Machine Learning: ML): AIを実現するための具体的な「手法」の一つです。コンピューターがデータから自動的に学習し、データの背景にあるパターンやルールを見つけ出す技術のことです。人間が一つ一つプログラムするのではなく、データを与えることでコンピューター自身が賢くなっていきます。AIという大きな目標を達成するためのアプローチの一つが機械学習です。
- ディープラーニング(Deep Learning: DL): 機械学習のさらに一部であり、特定の手法の一つです。「ニューラルネットワーク」という人間の脳神経系の仕組みを模した数理モデルを、多層(ディープ)に重ねて用いるのが特徴です。機械学習の中でも、特に複雑なパターン認識などで高い性能を発揮する技術として注目されています。
このように、AI ⊃ 機械学習 ⊃ ディープラーニング という関係性をまず押さえておきましょう。ディープラーニングは機械学習の一部であり、機械学習はAIを実現する技術の一部なのです。この全体像を理解した上で、それぞれの詳細を見ていきましょう。
機械学習(Machine Learning)とは?基本をおさらい
AIを実現する手法の一つである「機械学習(Machine Learning: ML)」とは、コンピューターがデータから自動的に学習し、そこに潜むパターンやルールを発見する技術のことです。人間が特定のタスク(例えば、スパムメールの判別)のためのルールを一つ一つ細かくプログラミングする代わりに、大量のデータ(例:過去のスパムメールと正常なメール)をコンピューターに与え、コンピューター自身に「どのようなメールがスパムであるか」の判断基準を学習させます。
機械学習のプロセスでは、多くの場合、人間がデータの中から「どの情報(特徴量 – とくちょうりょう)」に注目すべきかを事前に選び出し、コンピューターに教える必要があります。これを「特徴量エンジニアリング」と呼びます。
- 例:中古住宅の価格予測
- 人間が「家の広さ」「部屋数」「駅からの距離」「築年数」などが価格に影響しそうだと考え、これらの情報を特徴量として選びます。
- 過去の成約データ(各特徴量の値と実際の価格)をコンピューターに学習させます。
- コンピューターは、これらの特徴量と価格の関係性を学習し、新しい物件の特徴量を入力すると価格を予測できるようになります。
このように、機械学習では、人間が「どこに着目すべきか」というヒントを与えることで、コンピューターがデータから学習を進めるのが一般的です。学習方法には、正解データ付きで学習する「教師あり学習」、正解データなしでデータ内の構造を見つけ出す「教師なし学習」、試行錯誤を通じて最適な行動を学習する「強化学習」などの種類があります。
ディープラーニング(Deep Learning)とは?機械学習との違いの核心
「ディープラーニング(Deep Learning: DL)」は、前述した機械学習の特定の、そして非常に強力な手法の一つです。その最大の特徴は、人間の脳の神経細胞(ニューロン)のネットワーク構造を模した「ニューラルネットワーク」を多層(深く)に重ねて用いる点にあります。
ニューラルネットワークは、入力された情報を受け取り、複数の層を経て処理し、最終的な結果を出力する仕組みです。「ディープ(深い)」というのは、この中間層がたくさんあることを意味します。層が深いことで、より複雑なデータの関連性やパターンを捉えることが可能になります。
そして、ディープラーニングと従来の機械学習との最も核心的な違いは、「特徴量」の扱いにあります。
- 従来の機械学習: 多くの場合、人間がデータの中から重要な特徴量を選び出し、それをコンピューターに与える必要がありました。
- ディープラーニング: 大量のデータさえあれば、コンピューター自身がデータの中から学習に必要な特徴量を自動的に見つけ出してくれるのです。
例えば、猫の画像を認識する場合、従来の機械学習では人間が「猫の耳の形」「目の色」「ひげの有無」などを特徴量として指定する必要があったかもしれません。しかし、ディープラーニングでは、大量の猫の画像データを与えるだけで、AIが自動的に「猫らしさ」を判断するための特徴(最初は単純な線やエッジ、徐々に複雑な目や耳の形など)を、深い層構造の中で段階的に学習していきます。この「特徴量の自動抽出」能力こそが、ディープラーニングが特に画像認識や音声認識といった複雑な分野で目覚ましい成果を上げている理由なのです。
【徹底比較】ディープラーニングと機械学習の主な違い
ここまで、機械学習とディープラーニングの基本的な考え方と核心的な違い(特徴量の扱い)を見てきました。ここでは、さらにいくつかの観点から両者の違いを整理し、比較してみましょう。
- 違い①:特徴量の扱い【再掲・最重要】
- 機械学習: 人間が特徴量を設計・選択することが多い(特徴量エンジニアリング)。
- ディープラーニング: データから自動的に特徴量を学習する。
- 違い②:必要なデータ量
- 機械学習: 比較的小規模なデータセットでも機能する場合がある。特徴量が適切に設計されていれば、少ないデータでも有効なことがある。
- ディープラーニング: 高い性能を発揮するためには、一般的に非常に大量の学習データ(数万〜数百万以上)が必要。データが少ないと性能が出にくい。
- 違い③:計算コストとハードウェア
- 機械学習: アルゴリズムにもよるが、比較的計算コストは低く、一般的なCPUでも学習可能な場合が多い。
- ディープラーニング: 膨大な計算が必要となるため、高性能な計算資源、特に並列計算に優れたGPU(Graphics Processing Unit)が使われることが多い。学習に時間(数日〜数週間)がかかることも。
- 違い④:得意なタスク
- 機械学習: 表形式のような構造化データを用いた予測や分類問題(売上予測、顧客分類など)で依然として強力。
- ディープラーニング: 画像認識、音声認識、自然言語処理(翻訳、文章生成など)といった、非構造化データを扱う複雑なパターン認識タスクで特に高い性能を発揮する。
- 違い⑤:解釈性(ブラックボックス問題)
- 機械学習: 手法によっては(例:決定木)、なぜその予測・判断に至ったのか理由を説明しやすい。
- ディープラーニング: 非常に複雑なモデルのため、なぜその結論に至ったのか内部の判断プロセスを人間が理解するのが難しい場合がある(ブラックボックス問題)。ただし、説明可能性を高める研究(XAI)も進んでいる。
例え話で理解!ディープラーニングと機械学習の違い
少し複雑に感じるかもしれないので、身近な例え話を使って、ディープラーニングと機械学習の違いのイメージを掴んでみましょう。
例え話1:子供に「リンゴ」を教える
- 機械学習の教え方: 子供に「赤くて丸くて、このくらいの大きさで、こういう匂いがするものがリンゴだよ」と、リンゴを見分けるための特徴(色、形、大きさ、匂い)を具体的に教えてあげるイメージです。子供は教えられた特徴をもとに、新しい果物を見てリンゴかどうかを判断します。
- ディープラーニングの教え方: 子供に「これはリンゴだよ」「これはリンゴじゃないよ」というラベルが付いた、様々な種類のリンゴ(青リンゴ、傷のあるもの、かじられたもの等)と、リンゴ以外の果物の写真を、とにかくたくさん見せるイメージです。子供は大量の例を見るうちに、人間が言葉で教えなくても、自分自身で「リンゴらしさ」を判断するための複雑な特徴(微妙な色の違い、光沢、形状のパターンなど)を自然に学習していきます。
例え話2:美味しいカレーを作る
- 機械学習の作り方: 熟練シェフが作った詳細なレシピ(使うスパイスの種類と量、炒める時間、煮込む時間などが特徴量として細かく指定されている)通りに作るイメージです。レシピが良ければ美味しいカレーが作れます。
- ディープラーニングの作り方: 完成した美味しいカレー(データ)を何度も味見し、様々なスパイスや食材を大量に試しながら(学習)、どのような組み合わせや調理法が「美味しさ」に繋がるのか、その法則自体を自分で発見していくイメージです。最終的には、レシピには書かれていないような絶妙な味を生み出すかもしれません。
これらの例え話から、機械学習が「教えられた特徴」に強く依存するのに対し、ディープラーニングは「大量のデータから自ら特徴を学ぶ」というニュアンスの違いを感じ取っていただけるでしょうか。
それぞれの活用事例:どんな場面で使われている?
機械学習とディープラーニングは、その特性に応じて様々な分野で活用され、私たちの生活を便利にしています。現在、どのような場面で使われているのか、具体的な事例を見てみましょう。
機械学習(ML)の活用事例
- 迷惑メールフィルター: 受信したメールが迷惑メールか否かを、過去のデータから学習したパターン(特定の単語、送信元など)に基づいて自動で分類します。
- ECサイトのレコメンド機能: あなたの過去の購買履歴や閲覧履歴(データ)を分析し、あなたが興味を持ちそうな商品を「おすすめ」として表示します。
- 金融機関での不正利用検知: クレジットカードの利用履歴から、通常とは異なるパターン(不正利用の疑い)を検知します。
- 医療診断支援(構造化データに基づくもの): 患者の年齢、性別、検査数値などのデータから、特定の病気のリスクを予測します。
- 需要予測: 過去の販売データや天候データなどから、将来の商品需要を予測し、在庫管理などに役立てます。
ディープラーニング(DL)の活用事例
- 画像認識:
- スマートフォンの顔認証ロック解除
- 写真フォルダ内の人物や物体の自動タグ付け(例: Googleフォト)
- 医療画像(レントゲン、CTなど)からの病変検出支援
- 自動運転における歩行者や標識の認識
- AIによる画像生成(例:Stable Diffusion、Midjourneyなど)
- 音声認識:
- スマートスピーカーやスマートフォンの音声アシスタント(Siri、Googleアシスタント、Alexaなど)
- 会議の議事録自動作成、コールセンターでの通話内容テキスト化
- 自然言語処理:
- 高精度な機械翻訳(Google翻訳、DeepLなど)
- 人間のような自然な文章を作成するAI(ChatGPTに代表される大規模言語モデルLLMなど、2025年現在も進化中)
- 文章の感情分析(SNSでの評判分析など)
- チャットボットによる自動応答
- 異常検知: 工場の製造ラインでの製品の傷や欠陥の自動検出など
このように、特に画像、音声、自然言語といった複雑なデータを扱う分野で、ディープラーニングの活躍が目覚ましいことがわかります。
ディープラーニングと機械学習、どう使い分ける?
では、実際に何か問題を解決したいとき、ディープラーニングと機械学習のどちらの手法を選べば良いのでしょうか?いくつかの判断基準があります。
- 問題の種類とデータの性質
- 機械学習が適している場合
- 扱うデータが表形式などの構造化データである。
- 問題が比較的シンプルで、重要な特徴量が人間によって定義しやすい。
- 予測結果の理由を説明する必要性が高い(解釈性が求められる)。
- ディープラーニングが適している場合
- 扱うデータが画像、音声、テキストなどの非構造化データである。
- 問題が非常に複雑で、人間が特徴量を定義するのが困難である。
- (多少解釈性が低くても)とにかく高い予測精度が求められる。
- 機械学習が適している場合
- 利用可能なデータ量
- 機械学習: 比較的少ないデータ量でも、うまく特徴量を設定できれば機能することがある。
- ディープラーニング: 高い性能を出すには大量の学習データが必要不可欠。データが十分に確保できない場合は、他の機械学習手法の方が良い結果を出すこともある(転移学習などのテクニックもありますが、基本的には大量データが必要です)。
- 計算資源(コストと時間)
- 機械学習: 一般的なコンピューターでも学習可能な手法が多い。学習時間も比較的短い。
- ディープラーニング: 学習には高性能なGPUなどの計算資源が必要。学習に時間がかかることを覚悟する必要がある。予算や開発期間との兼ね合いも重要。
- 専門知識
- 機械学習: 様々なアルゴリズムがあり、比較的導入しやすいライブラリも多い。
- ディープラーニング: モデルの設計やチューニングには、より深い専門知識や経験が求められる場合がある。
必ずしも「ディープラーニングの方が優れている」というわけではありません。解決したい課題、データの種類と量、利用可能なリソースなどを総合的に判断し、「適材適所」で使い分けることが重要です。
まとめ:ディープラーニングと機械学習の違いを理解し、AI技術への理解を深めよう
今回は、AI技術の中核をなす「機械学習」と、その一分野である「ディープラーニング」について、両者の関係性から基本的な仕組み、そして核心的な違いまでを解説しました。
画像認識や自然言語処理(ChatGPTなど)といった目覚ましいAIの進化の背景には、ディープラーニングの発展があります。しかし、機械学習も依然として多くの分野で活用される重要な技術です。両者の違いと関係性を正しく理解することで、ニュースなどで報じられるAI技術の話題がより深く理解できるようになり、その可能性や課題についても考えられるようになるでしょう。この記事が、皆さんのAI技術への理解を深める一助となれば幸いです。
が急速に進化し、私たちの生活やビジネスに浸透する中で、「機械学習」や「ディープラーニング」といった言葉を耳にする機会が増えました。これらの言葉は ...){kind=link}